HTTrack
Описание HTTrack
HTTrack — это бесплатная, открытая, простая в использовании утилита для оффлайн просмотра веб-сайтов.
Она позволяет загружать веб-сайты из Интернета в локальный каталог, повторяя структуру директорий, получая HTML, изображения и другие файлы с сервера на ваш компьютер. HTTrack организует оригинальную структуру относительных ссылок. Просто откройте страницу «зазеркаленного» веб-сайта в вашем браузере и вы можете просматривать его переходя по ссылкам так, будто бы вы просматриваете его онлайн. HTTrack также может обновить существующий зазеркаленный сайт и возобновить прерванные загрузки. HTTrack полностью настраиваемая, имеет встроенную систему помощи.
HTTrack — это версия для Linux.
WinHTTrack — это версия HTTrack для Windows 2000/XP/Vista/Seven, а WebHTTrack — это графический интерфейс версий Linux/Unix/BSD.
Особенности:
- Версии доступны для Windows, Linux, Sun Solaris и других Unix подобных систем (другие платформы могут быть вскоре добавлены)
- Многоязычный интерфейс для Windows и Linux/Unix
- Бесплатное программное обеспечение (GPL) (исходный код открыт)
- Создание зеркал одного сайта или более чем одного за один раз (с общими ссылками)
- Настройка уровня глубины (рекурсии)
- Быстрое обновление загруженных сайтов и возобновление прерванных загрузок (из-за обрыва соединений, вылетов и т. д.)
- Фильтрация файлов по типу, расположению ссылок, глубины структуры, размеру файлов, размеру сайтов, принимаемым или отбрасываемым сайтом или именам файлов (с продвинутыми символами подстановки).
- Управление таймаутом и минимальной скоростью передачи для пропуска самых медленных сайтов
- Мастер для выбора ссылок, которые должны быть загружены (ссылки для принятия/отказа, все домены, все директории)
- Режим множества подключений (по умолчанию: 4 подключения) делает максимальной скорость загрузки
- HTTP компрессия (gzip..)
- Поддержка прокси для максимальной скорости, есть опциональная аутентификация
- Повторное получение (возобновление) частично скаченных файлов (HTTP/1.1)
- Имена файлов сохраняются с оригинальной структурой или используется расщеплённый режим (один каталог для html, один каталог для изображений), опция имена файлов dos 8-3 и определённая пользователем структура
- Автоматический переключатель для ошибок «Перемещено» ("Moved")
- Разбор HTML и анализ тэгов, включая код javascript/включённый HTML код
- Базовый разбор java и Flash
- Интегрированный DNS кэш
- Родная поддержка https и ipv6
- Опциональный файл журнала с записью ошибок и комментариев
- Определяемый пользователем путь для зеркала и файлов логов
- Работает как программа командной строки или через оболочку как для личного (захвата), так и для профессионального использования (онлайн веб-зеркало)
Домашняя страница: http://www.httrack.com/
Автор: Xavier Roche
Лицензия: GPLv3
Справка по HTTrack
использование:
![]()
с опциями представленными ниже: (* - звёздочка, показывает опции по умолчанию)
Обычные опции:
O путь для зеркала/файлов логов+кэша (-O путь_зеркала[,путь_кэша_и_лог_файлов]) (--path <параметр>)
Опции действий:
w *создание зеркала веб-сайта (--mirror)
W полуавтоматическое создание зеркала веб-сайта (задаются вопросы) (--mirror-wizard)
g просто получить файлы (сохранить в текущей директории) (--get-files)
i продолжить прерванное создание зеркала используя кэш (--continue)
Y сделать зеркало ВСЕХ ссылок, размещённых на страницах первого уровня (зеркало ссылок) (--mirrorlinks)
Опции прокси:
P использовать прокси (-P прокси:порт or -P пользователь:пароль@прокси:порт) (--proxy <параметры>)
%f *использовать прокси для ftp (f0 не использовать) (--httpproxy-ftp[=N])
%b использовать это локальное имя хоста для создания/отправки запросов (-%b имя хоста) (--bind <параметр>)
Ограничительные опции:
rN установить глубину зеркала на N (* r9999) (--depth[=N])
%eN установить глубину внешних ссылок на N (* %e0) (--ext-depth[=N])
mN максимальная длина файла для не-html файла (--max-files[=N])
mN,N2 максимальная длина файла для не-html (N) и html (N2)
MN максимальный размер, который в общей сложности может быть выгружен/просканирован (--max-size[=N])
EN максимальное время создания зеркала в секундах (60=1 минута, 3600=1 час) (--max-time[=N])
AN максимальная скорость передачи данных в байтах/секунду (1000=1KB/s max) (--max-rate[=N])
%cN максимальное количество подключений/секунду (*%c10) (--connection-per-second[=N])
GN поставить передачу на паузу, если достигнуто N байт и ожидать, пока не будет удалён блокирующий файл (--max-pause[=N])
Управление потоком:
cN количество одновременных подключений (*c8) (--sockets[=N])
TN таймаут, количество секунд, прошедших после того, как ссылка не отвечает (--timeout[=N])
RN количество попыток в случае таймаута или не фатальных ошибок (*R1) (--retries[=N])
JN контроль глушения трафика, минимальная скорость передачи (байт/секунду) допустимая для ссылки (--min-rate[=N])
HN хост покидается, если: 0=никогда, 1=таймаут, 2=медленный, 3=таймаут или медленный (--host-control[=N])
Опции ссылок:
%P *расширенный разбор, попытка парсить все ссылки, даже в неизвестных тегах или Javascript (%P0 не используется) (--extended-parsing[=N])
n получать не-html файлы 'рядом' с html файлом (например: изображение, размещённое снаружи) (--near)
t тестировать все URLs (даже запрещённые) (--test)
%L <файл> добавить все URL имеющиеся в этом текстовом файле (один URL на строку) (--list <параметр>)
%S <файл> добавить все правила сканирования, размещённые в этом текстовом файле (одно правило на строку) (--urllist <параметры>)
Опции сборки:
NN тип структуры (0 *оригинальная структура, 1+: смотри ниже) (--structure[=N])
или определённая пользователем структура (-N "%h%p/%n%q.%t")
%N проверка замедленного типа, не делать каких-либо тестов ссылок, но вместо этого ожидать загрузки файлов (экспериментальная) (%N0 не использовать, %N1 использовать для неизвестных расширений, * %N2 всегда использовать)
%D тип проверки кэшированной задержки, не ожидать удалённых типов для обновления, для их ускорения (%D0 ждать, * %D1 не ждать) (--cached-delayed-type-check)
%M генерировать RFC MIME-инкапсулированный полный архив (.mht) (--mime-html)
LN длинные имена (L1 *длинные имена / L0 8-3 преобразование / L2 ISO9660 совместимые) (--long-names[=N])
KN сохранять первоначальные ссылки (например, http://www.adr/link) (K0 *относительные ссылки, K абсолютные ссылки, K4 оригинальные ссылки, K3 абсолютные URI ссылки, K5 ссылки прозрачного прокси) (--keep-links[=N])
x заменять внешние html ссылки страницей ошибки (--replace-external)
%x не включать какие-либо пароли для защищённый внешним паролем веб-сайтов (%x0 включать) (--disable-passwords)
%q *включать строку запроса для локальных файлов (бесполезна, только для информационных целей) (%q0 не включать) (--include-query-string)
o *генерировать выводной html файл в случае ошибки (404..) (o0 не генерировать) (--generate-errors)
X *удалить старые файлы после обновления (X0 сохранять удаления) (--purge-old[=N])
%p сохранять html файлы 'как есть' (идентично '-K4 -%F ""') (--preserve)
%T конвертация ссылок в UTF-8 (--utf8-conversion)
Опции паука:
bN принимать кукиз в cookies.txt (0=не принимать,* 1=принимать) (--cookies[=N])
u проверять тип документа, если неизвестный (cgi,asp..) (u0 не проверять, * u1 проверять, но /, u2 всегда проверять) (--check-type[=N])
j *парсить Java классы (j0 не парсить, битовая маска: |1 парсить по умолчанию, |2 не парсить .class |4 не парсить .js |8 не быть агрессивным) (--parse-java[=N])
sN следовать robots.txt и мета тэгам robots (0=никогда,1=иногда,* 2=всегда, 3=всегда (даже строгие правила)) (--robots[=N])
%h принудительные HTTP/1.0 запросы (уменьшить возможности обновления, только для старых серверов и прокси) (--http-10)
%k сохранить keep-alive если возможно, значительно уменьшает задержку для маленьких файлов и тестовых запросов (%k0 не использовать) (--keep-alive)
%B толератные запросы (принимать фиктивные ответы на некоторых серверах, но не стандарт!) (--tolerant)
%s хаки обновления: различные хаки для ограничения повторной отправки при обновлении (идентичный размер, фиктивные ответы..) (--updatehack)
%u url хаки: различные хаки для ограничения дубликатов URL (обрезать //, www.foo.com==foo.com..) (--urlhack)
%A предполагать что тип (cgi,asp..) всегда связан с типом mime (-%A php3,cgi=text/html;dat,bin=application/x-zip) (--assume <параметр>)
сокращение: '--assume standard' эквивалентно -%A php2 php3 php4 php cgi asp jsp pl cfm nsf=text/html
может также использоваться для форсирования конкретных типов файлов: --assume foo.cgi=text/html
@iN Интернет протокол (0=оба ipv6+ipv4, 4=ipv4 только, 6=ipv6 только) (--protocol[=N])
%w отключить конкретные внешние mime модули (-%w htsswf -%w htsjava) (--disable-module <параметр>)
ID браузера:
F user-agent поле, отправляемое в HTTP headers (-F "имя пользовательского агента") (--user-agent <параметр>)
%R отправляемое дефолтное поле реферера HTTP headers (--referer <параметр>)
%E с email адреса отправленного в заголовках HTTP (--from <параметр>)
%F строка футера в Html коде (-%F "Mirrored [from host %s [file %s [at %s]]]" (--footer <параметр>)
%l предпочитаемый язык (-%l "fr, en, jp, *" (--language <параметр>)
%a принимаемый формат (-%a "text/html,image/png;q=0.9,*/*;q=0.1" (--accept <параметр>)
%X строка дополнительных заголовков HTTP (-%X "X-Magic: 42" (--headers <параметр>)
Лог, индекс, кэш
C создать/использовать кэш для обновления и повторных попыток (C0 без кэша,C1 кэш является собственностью,* C2 тест обновления перед) (--cache[=N])
k сохранять все файлы в кэше (не полезно, если файлы на диске) (--store-all-in-cache)
%n не загружать повторно локально удалённые файлы (--do-not-recatch)
%v показывать на экране имена загружаемых файлов (в реальном времени) - * %v1 короткая версия - %v2 полная анимация (--display)
Q не вести лог - тихий режим (--do-not-log)
q без запросов — тихий режим (--quiet)
z лог — дополнительная информация (--extra-log)
Z лог - отладка (--debug-log)
v лог на экране (--verbose)
f *лог в файлах (--file-log)
f2 один единый лог файл (--single-log)
I *сделать индекс (I0 не делать) (--index)
%i сделать верхний индекс для директории проекта (* %i0 не делать) (--build-top-index)
%I сделать поисковый индекс для этого зеркала (* %I0 не делать) (--search-index)
Экспертные опции:
pN режим приоритета: (* p3) (--priority[=N])
p0 просто сканировать, не сохранять что-либо (для проверки ссылок)
p1 сохранить только html файлы
p2 сохранить только не html файлы
*p3 сохранить все файлы
p7 получить html файлы перед, затем обрабатывать другие файлы
S оставаться в этой же директории (--stay-on-same-dir)
D *можно только спускаться вниз в поддиректории (--can-go-down)
U можно только подниматься в директории (--can-go-up)
B можно подниматься и опускаться по структурам директорий (--can-go-up-and-down)
a *оставаться на том же адресе (--stay-on-same-address)
d оставаться на том же основном домене (--stay-on-same-domain)
l оставаться в той же доменной зооне (пример: .com) (--stay-on-same-tld)
e идти куда угодно в сети (--go-everywhere)
%H отладка HTTP заголовков в логфайле (--debug-headers)
Опции для гуру: (если возможно НЕ используйте)
#X *использовать оптимизированный движок (проверка границ ограничения памяти) (--fast-engine)
#0 тест фильтра (-#0 '*.gif' 'www.bar.com/foo.gif') (--debug-testfilters <параметр>)
#1 упрощённый тест (-#1 ./foo/bar/../foobar)
#2 тест типа (-#2 /foo/bar.php)
#C список кэша (-#C '*.com/spider*.gif' (--debug-cache <параметр>)
#R ремонт кэша (повреждённого кэша) (--repair-cache)
#d отладка парсера (--debug-parsing)
#E извлечь метаданные кэша new.zip в meta.zip
#f всегда очищать файлы лога (--advanced-flushlogs)
#FN максимальное число фильтров (--advanced-maxfilters[=N])
#h информация о версии (--version)
#K сканировать стандартный ввод (отладка) (--debug-scanstdin)
#L максимальное число ссылок (-#L1000000) (--advanced-maxlinks[=N])
#p показать продвинутую информацию о прогрессе (--advanced-progressinfo)
#P поймать URL (--catch-url)
#R старые подпрограммы FTP (отладка) (--repair-cache)
#T сгенерировать ops. log передачи каждые минуты (--debug-xfrstats)
#u время ожидания (--advanced-wait)
#Z сгенерировать статистику скорости передачи каждые минуты (--debug-ratestats)
Опасные опции: (НЕ используйте, если вы не знаете точно, что вы делаете)
%! обход встроенных лимитов безопасности, предназначенных для избежания жалоб на пропускную способность (пропускная способность, одновременные подключения) (--disable-security-limits)
ВАЖНОЕ ЗАМЕЧАНИЕ: ОПАСНЫЕ ОПЦИИ, ПРЕДНАЗНАЧЕНЫ ТОЛЬКО ДЛЯ ЭКСПЕРТОВ
ИСПОЛЬЗУЙТЕ ИХ С КРАЙНЕЙ ОСТОРОЖНОСТЬЮ
Опции, присущствующие только во командной строке:
V выполнять системную команды после каждых файлов ($0 — это имя файла: -V "rm \$0") (--userdef-cmd <параметр>)
%W использовать функцию внешней библиотеки как обёртку (-%W myfoo.so[,myparameters]) (--callback <параметр>)
Подробности: Опция N
N0 Структура сайта (по умолчанию)
N1 HTML в web/, изображения/другие файлы в web/images/
N2 HTML в web/HTML, изображения/другие файлы в web/images
N3 HTML в web/, изображения/другие файлы в web/
N4 HTML в web/, изображения/другое в web/xxx, где xxx это расширения файлов (все gif будут помещены в web/gif, например)
N5 Изображения/другое в web/xxx и HTML в web/HTML
N99 Все файлы в web/, со случайными именами (безделушка!)
N100 Структура сайта, без www.domain.xxx/
N101 Идентично N1 кроме того, что "web" заменена именем сайта
N102 Идентично N2 кроме того, что "web" заменена именем сайта
N103 Идентично N3 кроме того, что "web" заменена именем сайта
N104 Идентично N4 кроме того, что "web" заменена именем сайта
N105 Идентично N5 кроме того, что "web" заменена именем сайта
N199 Идентично N99 кроме того, что "web" заменена именем сайта
N1001 Идентично N1 кроме того, что нет директории "web"
N1002 Идентично N2 кроме того, что нет директории "web"
N1003 Идентично N3 кроме того, что нет директории "web" (опция устанавливается для опции g)
N1004 Идентично N4 кроме того, что нет директории "web"
N1005 Идентично N5 кроме того, что нет директории "web"
N1099 Идентично N99 кроме того, что нет директории "web"
Подробности: User-defined option N
'%n' Имя файла без типа файла (пример: image)
'%N' Имя файла, включая тип файла (exпример image.gif)
'%t' File type (пример: gif)
'%p' Путь [без конечного /] (пример: /someimages)
'%h' Имя хоста (пример: www.someweb.com)
'%M' URL MD5 (128 бит, 32 ascii байты)
'%Q' строка запроса MD5 (128 бит, 32 ascii байты)
'%k' полная строка запроса
'%r' имя протокола (пример: http)
'%q' малая строка запроса MD5 (16 бит, 4 ascii байты)
'%s?' Короткое имя версии (пример: %sN)
'%[параметр]' значение параметра в строке запроса
'%[param:before:after:empty:notfound]' продвинутое извлечение переменных
Подробности: Заданные пользователем опции N и продвинутое извлечение переменных
%[param:before:after:empty:notfound]
param : имя параметра
before : предваряющая строка, если параметр найден
after : последующая строка, если параметр был найден
notfound : строка заменитель, если параметр не может быть найден
empty : заменитель строки, если параметр пуст
все поля, кроме первого (имя параметра), могут быть пустыми
Подробности: Опция K
K0 foo.cgi?q=45 -> foo4B54.html?q=45 (относительные URI, по умолчанию)
K -> http://www.foobar.com/folder/foo.cgi?q=45 (абсолютные URL) (--keep-links[=N])
K3 -> /folder/foo.cgi?q=45 (абсолютные URI)
K4 -> foo.cgi?q=45 (первоначальные URL)
K5 -> http://www.foobar.com/folder/foo4B54.html?q=45 (URL прозрачного прокси)
Сокращения:
--mirror <URL> *создать зеркало сайта(ов) (по умолчанию)
--get <URL> получить указанные файлы, не искать другие URL (-qg)
--list <текстовый файл> добавить все URL находящиеся в текстовом файле (-%L)
--mirrorlinks <URL> сделать зеркало всех ссылок на страницах первого уровня (-Y)
--testlinks <URL> тестировать ссылки на страницах (-r1p0C0I0t)
--spider <URL> пройтись по сайту, тестировать ссылки: сообщать об ошибках и предупреждениях (-p0C0I0t)
--testsite <URL> идентично --spider
--skeleton <URL> сделать зеркало, но получить только файлы html (-p1)
--update обновить зеркало, без подтверждения (-iC2)
--continue продолжить зеркало, без подтверждения (-iC1)
--catchurl создать временный прокси для захвата URL или из форм post URL
--clean очистить кэш и файлы логов
--http10 принудительные запросы http/1.0 (-%h)
Подробности: Опция %W: Прототипы внешних обратных вызовов
смотрите htsdefines.h
Руководство по HTTrack
Страница man присутствует, но почти в точности повторяет справку.
Примеры запуска HTTrack
сделать зеркало сайта www.someweb.com/bob/ и только этого сайта
httrack www.someweb.com/bob/
сделать зеркало двух сайтов вместе (с общими ссылками) и принять любые .jpg файлы на .com сайте
httrack www.someweb.com/bob/ www.anothertest.com/mike/ +*.com/*.jpg -mime:application/*
означает получить все файлы, начинающиеся с bobby.html, с 6 уровневой глубиной ссылок и возможностью переходить куда угодно в сети
httrack www.someweb.com/bob/bobby.html +* -r6
запустить паук на www.someweb.com/bob/bobby.html используя прокси
httrack www.someweb.com/bob/bobby.html --spider -P proxy.myhost.com:8080
обновить зеркало в текущей директории
httrack --update
перейти в интерактивный режим
httrack
продолжить зеркало в текущем каталоге
httrack --continue
Установка HTTrack
Установка в Kali Linux, Debian, Linux Mint, Ubuntu
sudo apt-get install httrack webhttrack
Установка в BlackArch
pacman -S httrack
Графический интерфейс HTTrack
Запустите:
webhttrack
Теперь веб-интерфейс доступен по адресу http://localhost:8080
Скриншоты HTTrack

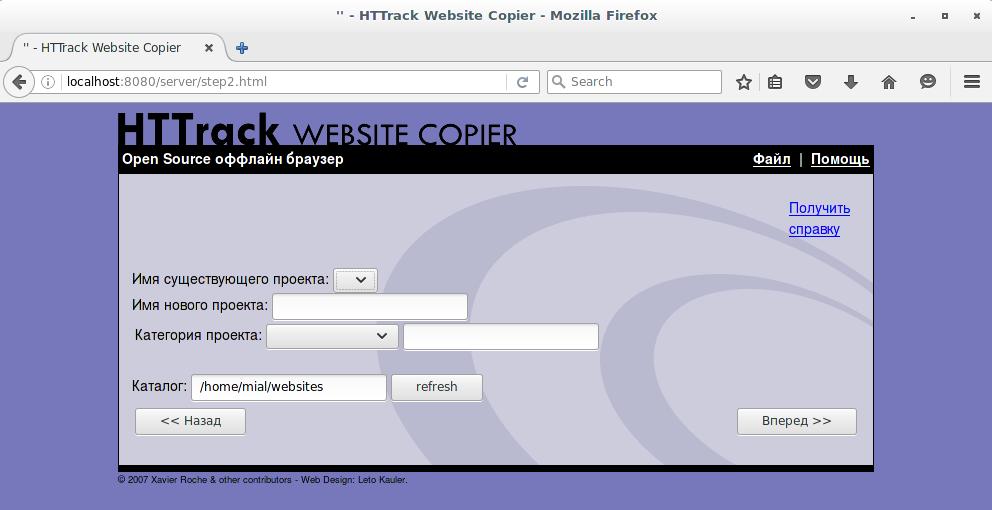
Comments are Closed